AI Semantic Categorization Proof of Concept
Description:
Created a python project to categorize data with Google and OpenAI LLM models, visualized the test data with Tableau, then utilized prompt engineering to achieve 100% categorization accuracy.
Business Objective:
Evaluate the feasibility of using LLMs to scan JSON payloads (form data) to perform reliable categorization tasks
My Role:
Freelance Consultant
Completion Date:
February 2025
Summary and Results
I was asked to help evaluate the feasibility of using LLMs to scan JSON payloads (form data) to perform reliable categorization tasks. This proof of concept would help determine whether further investment by the organization was warranted.
Approach:
- Developed code to send test data (in the form of JSON payloads) to multiple LLM models and saved the results in a database
- Developed a set of synthetic eval data to test common and edge cases
- Iterated on the prompt context, AI Model, and confidence threshold over 6 rounds of testing encompassing thousands of runs against the test data
Results:
- After 6 rounds of iteration, I was able to improve the system from 93% to 100% accuracy in categorizing the 75 test payloads giving strong confidence that it was worth investing further resources into a full scale solution.
Lessons Learned:
- Ask for a Structured response: When asking an LLM to give you a consistent, structured response, ask for it in JSON. JSON is easy to parse, and LLMs understand the syntax
- Plan on variability: If your task relies on an LLMs judgement or effort, there will be variability in response. This is represented in my charts by bar length and size of dots. Instead of asking for a Yes/No answer that would have flipped back and forth, I asked for a confidence score, worked to reduce variance by improving my prompt, and adjusted my “confidence threshold” to find a balance that worked well.
- Test and Improve your prompt: OpenAI offers the option to build custom trained models but encourages you to improve your prompt first. In my situation, by encouraging thoroughness at the beginning, middle and end, as well as improving the structure of my prompt with the “right amount” of detail I was able to achieve 100% success without a custom model.
The visuals below helped identify which models were performing the best, what an appropriate confidence threshold should be, and what types of questions needed to be addressed by improving prompt context.
Data Visuals 1
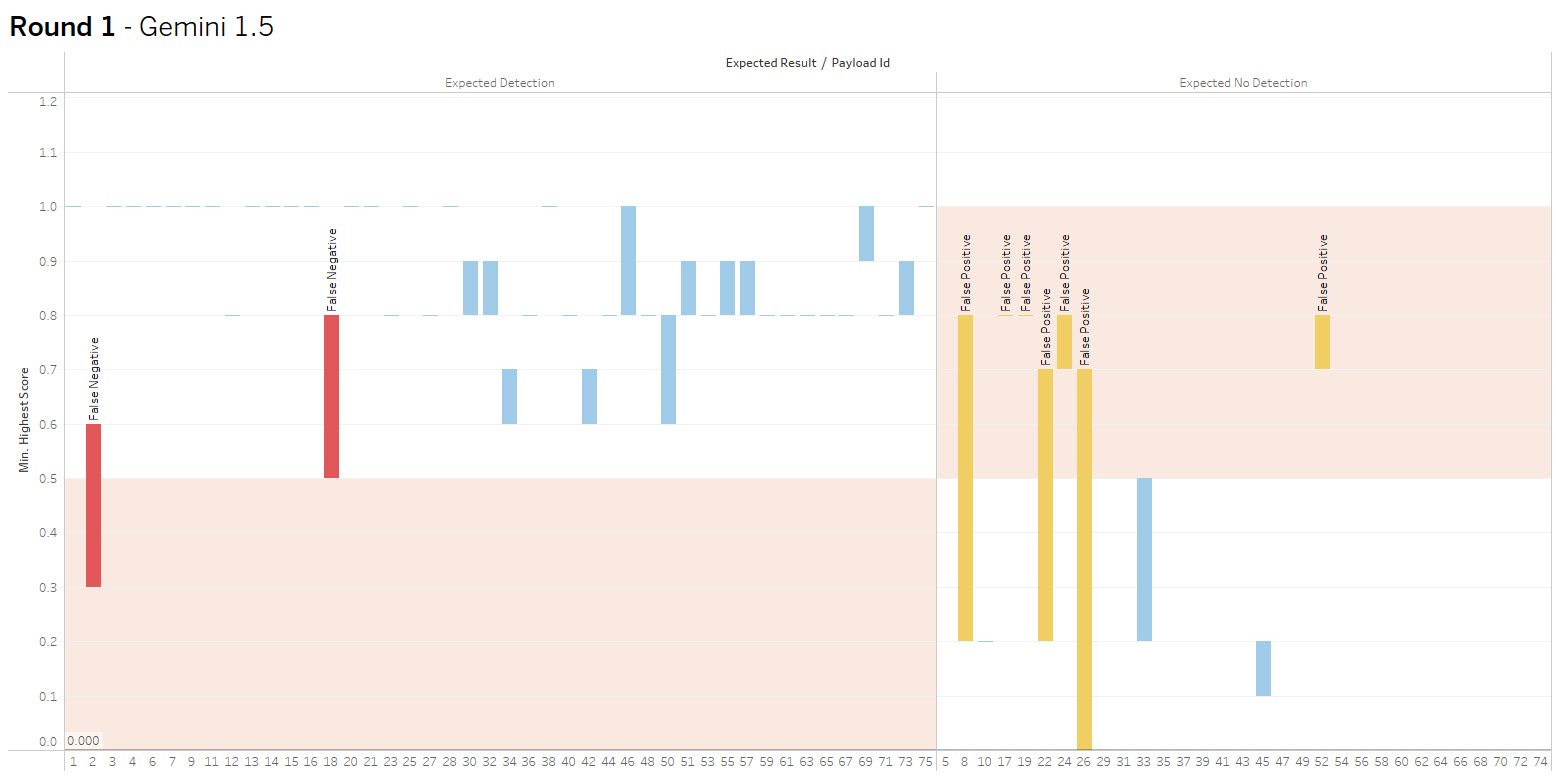
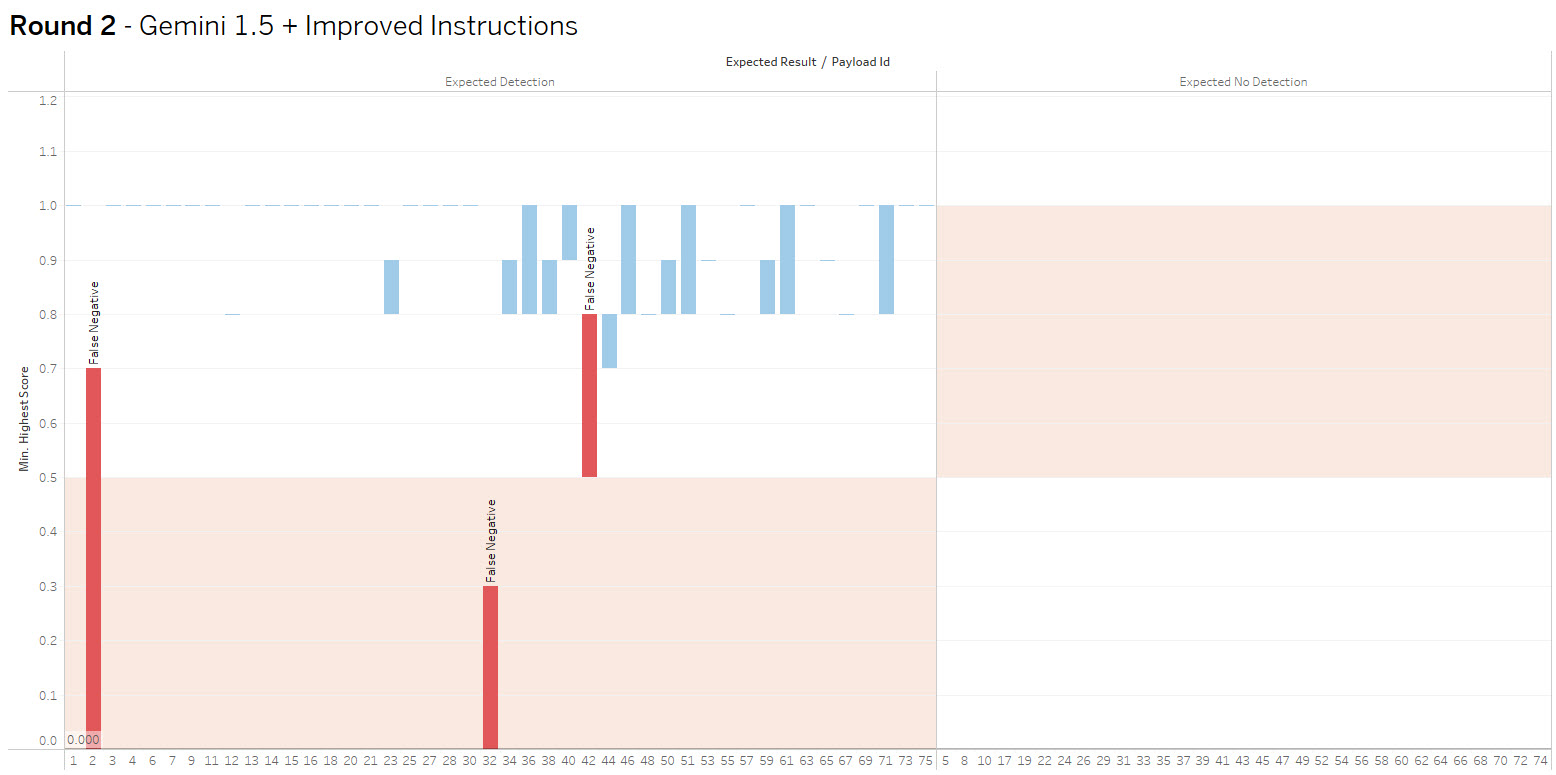
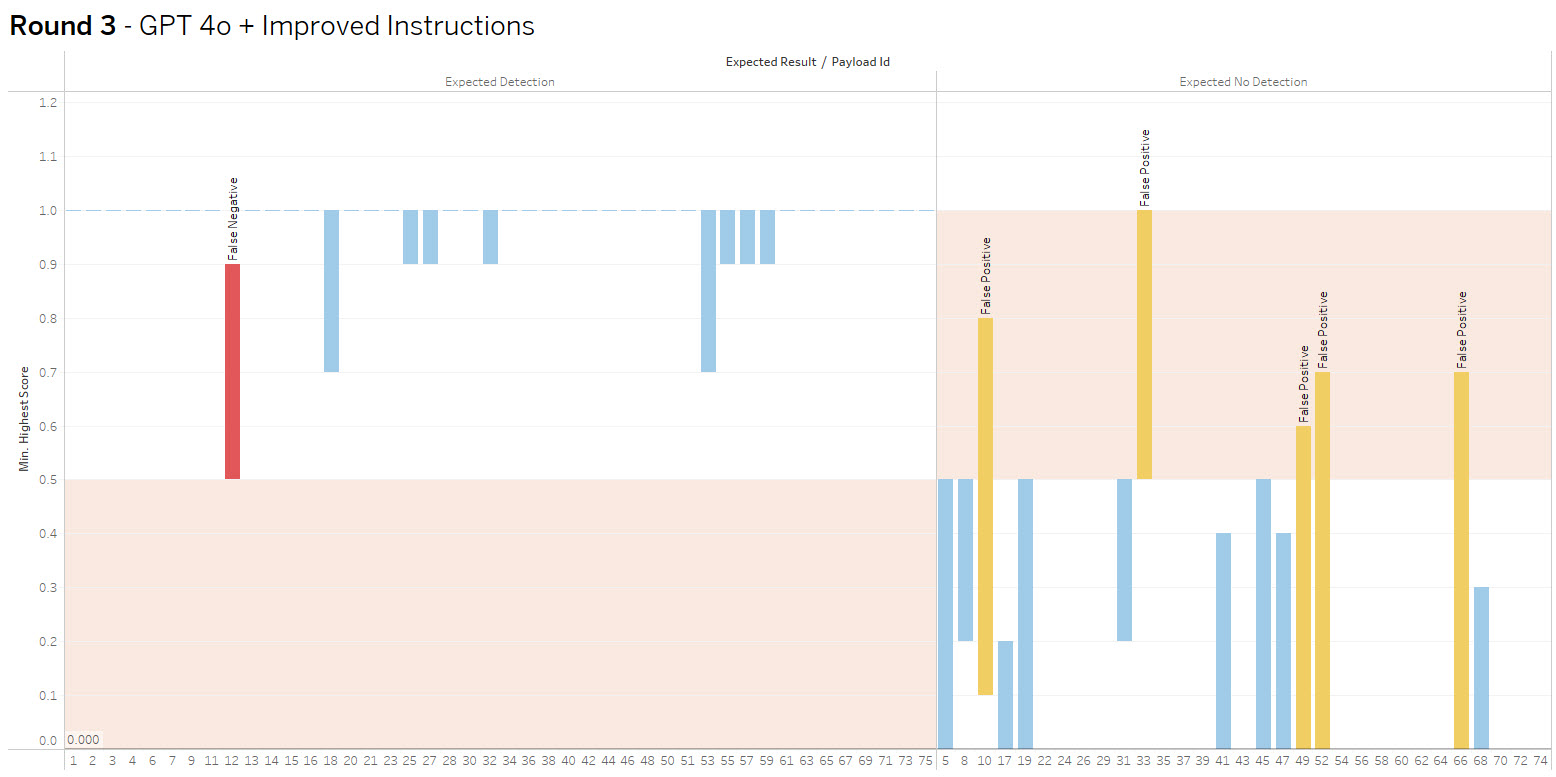
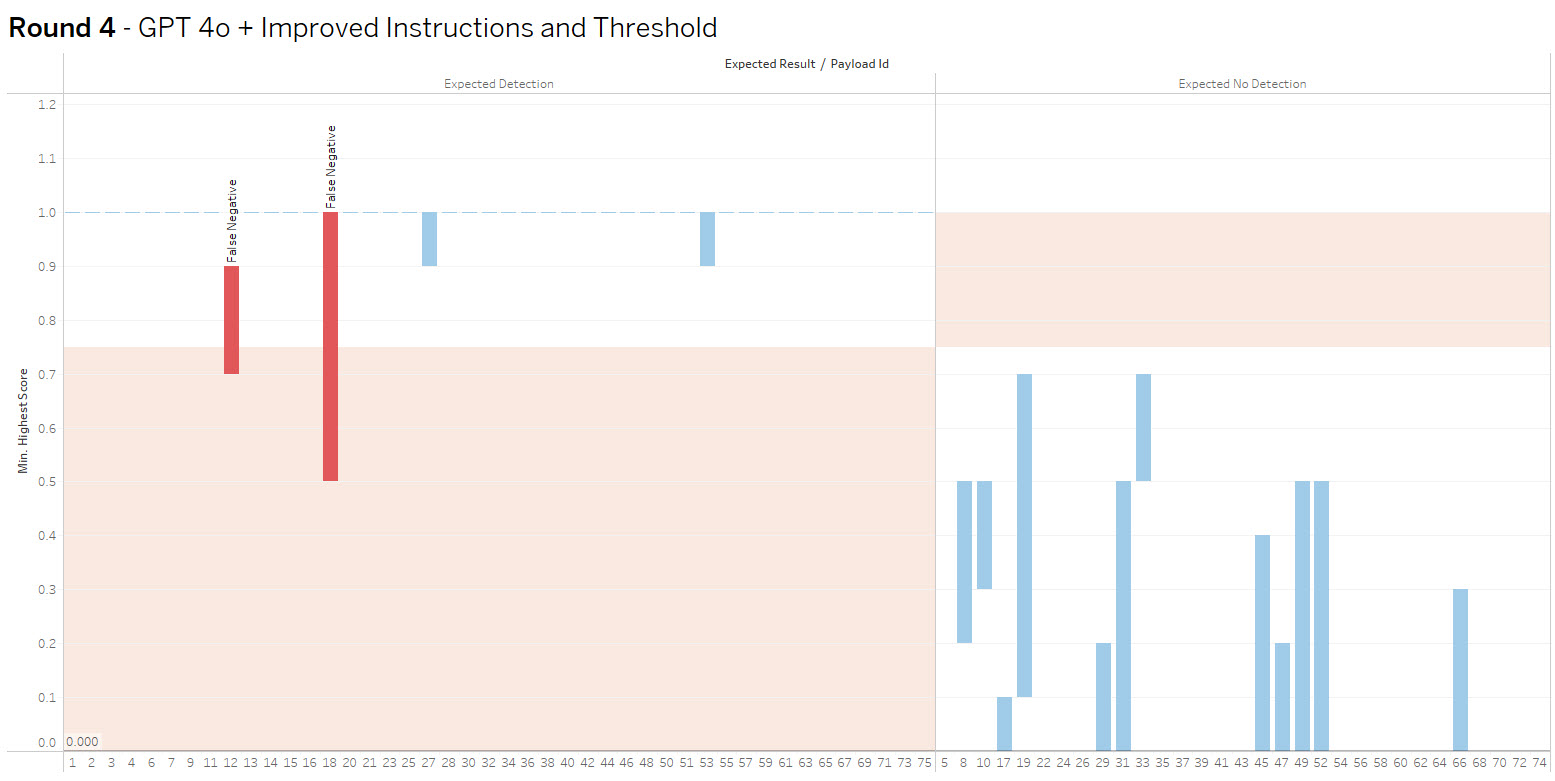
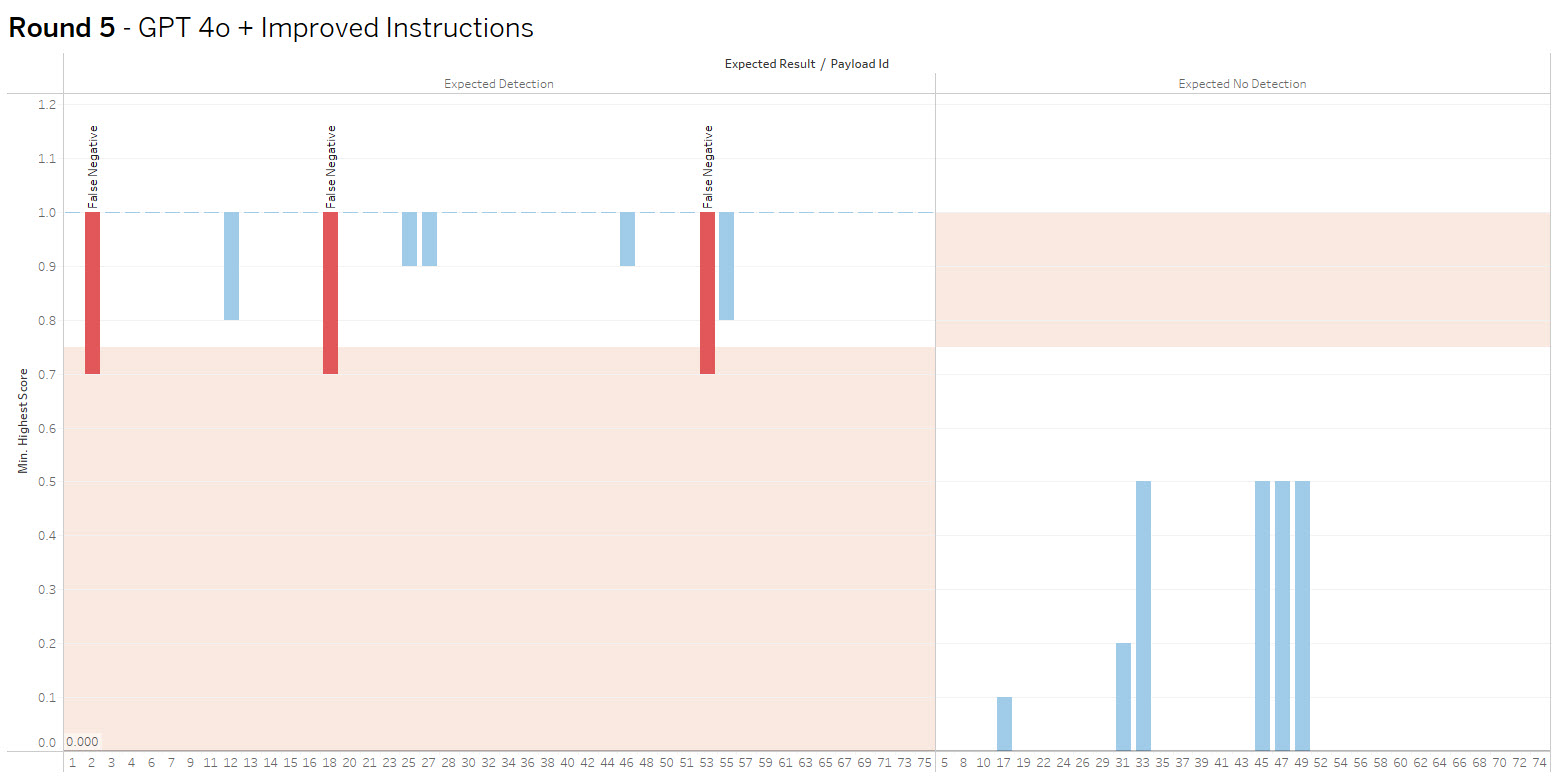
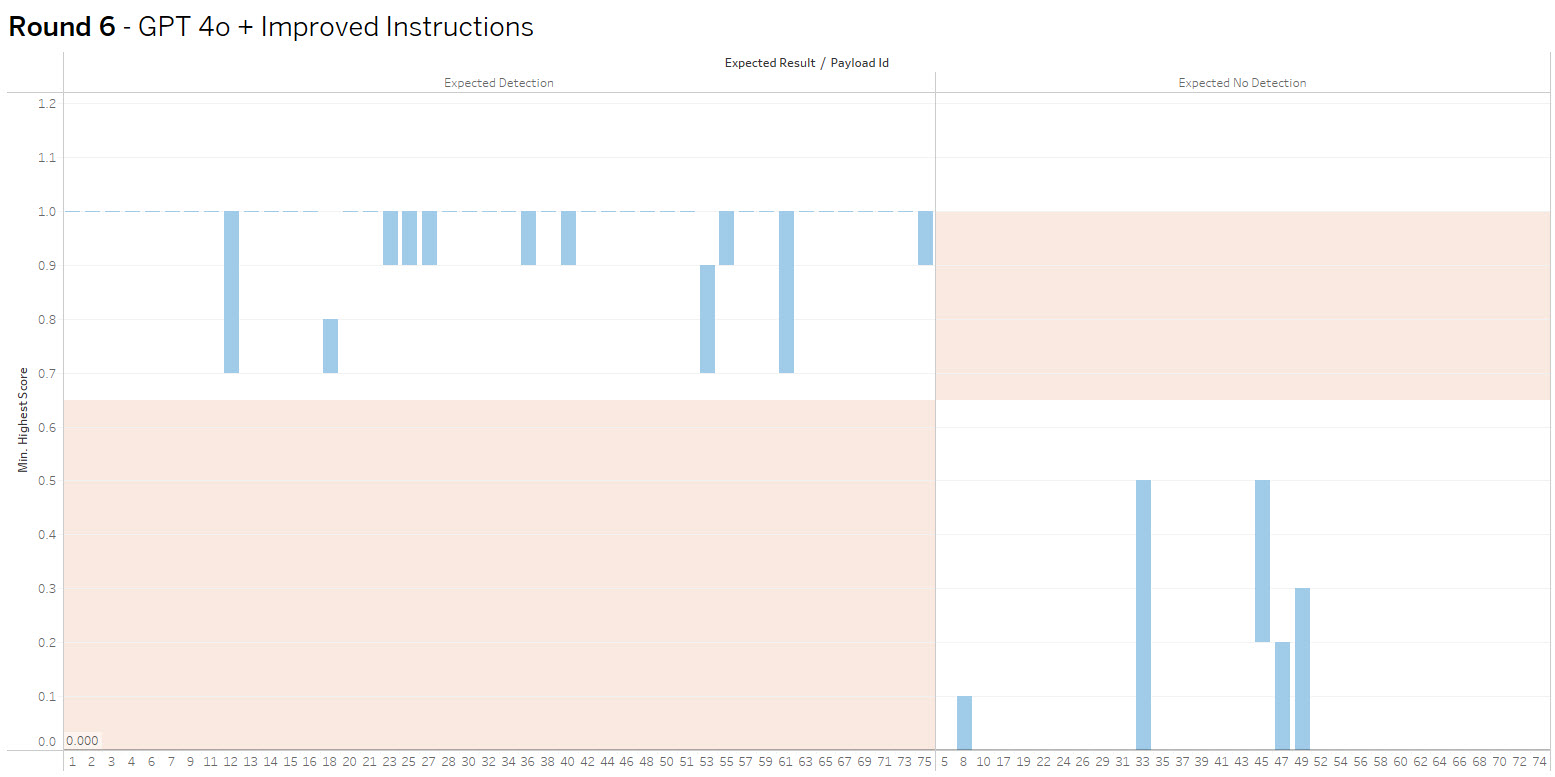
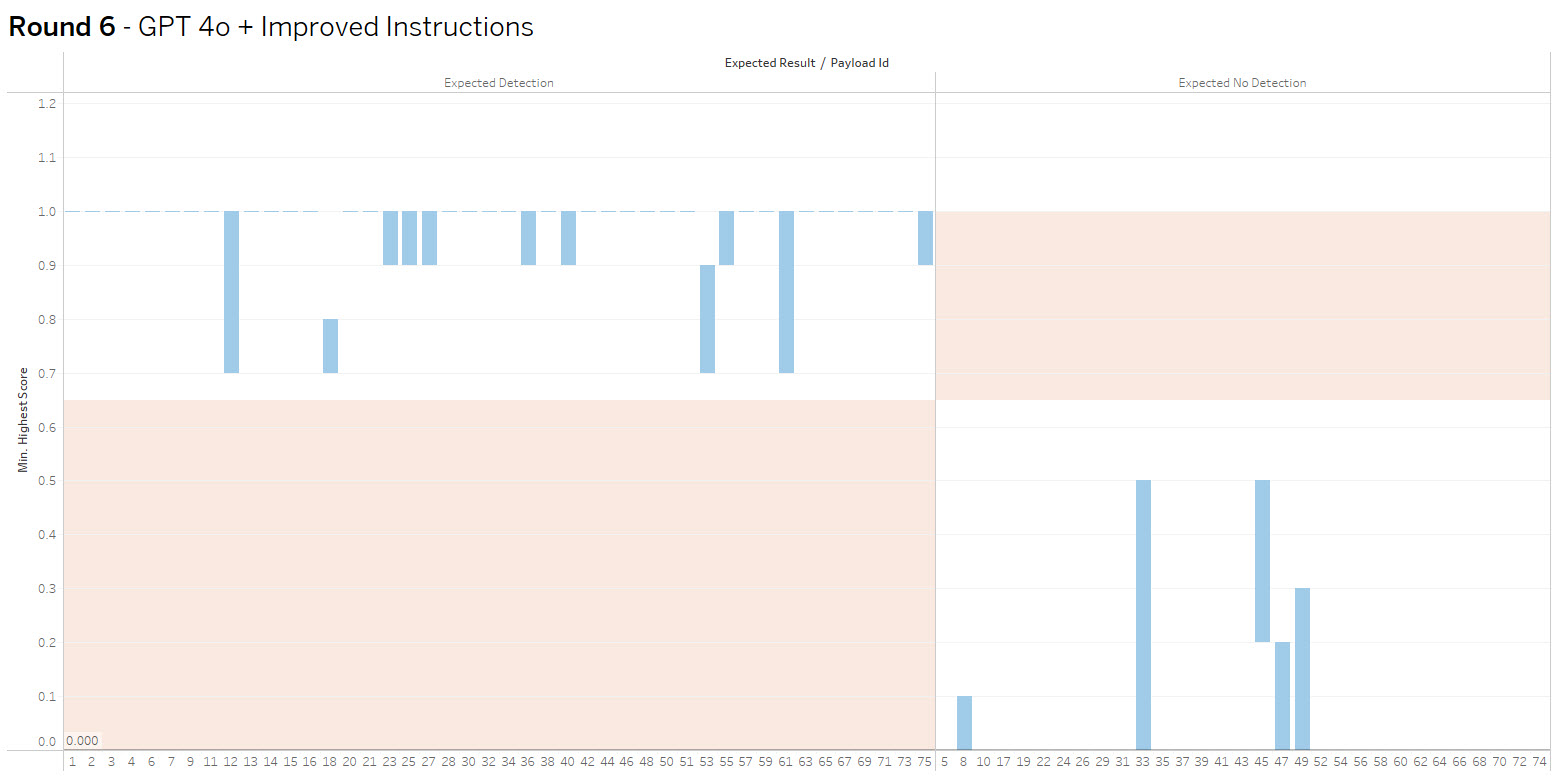
The bar height shows the range of values received, crossing into the red indicates false positive or negative. The goal is to increase accuracy and consistency.
Data Visuals 2
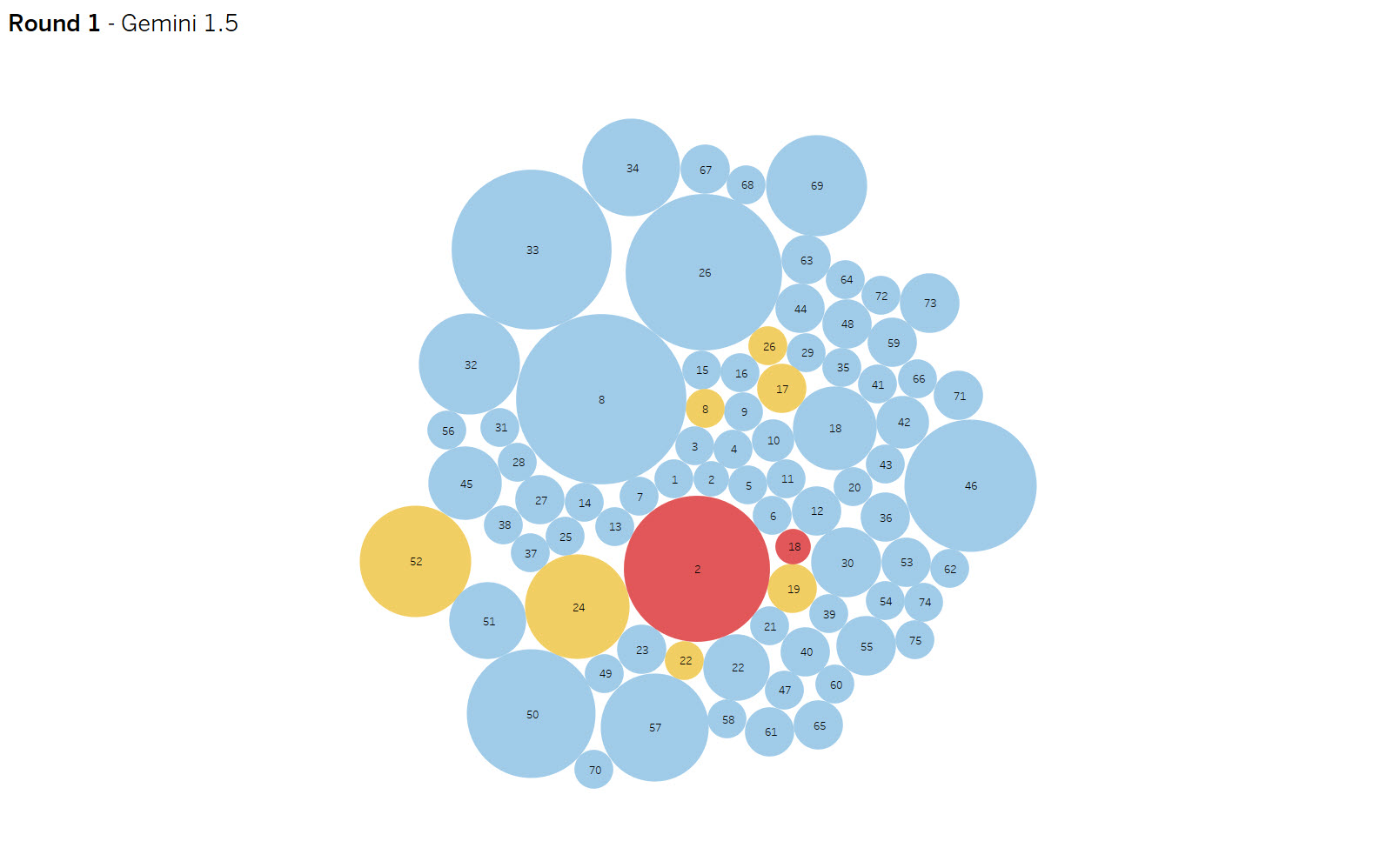
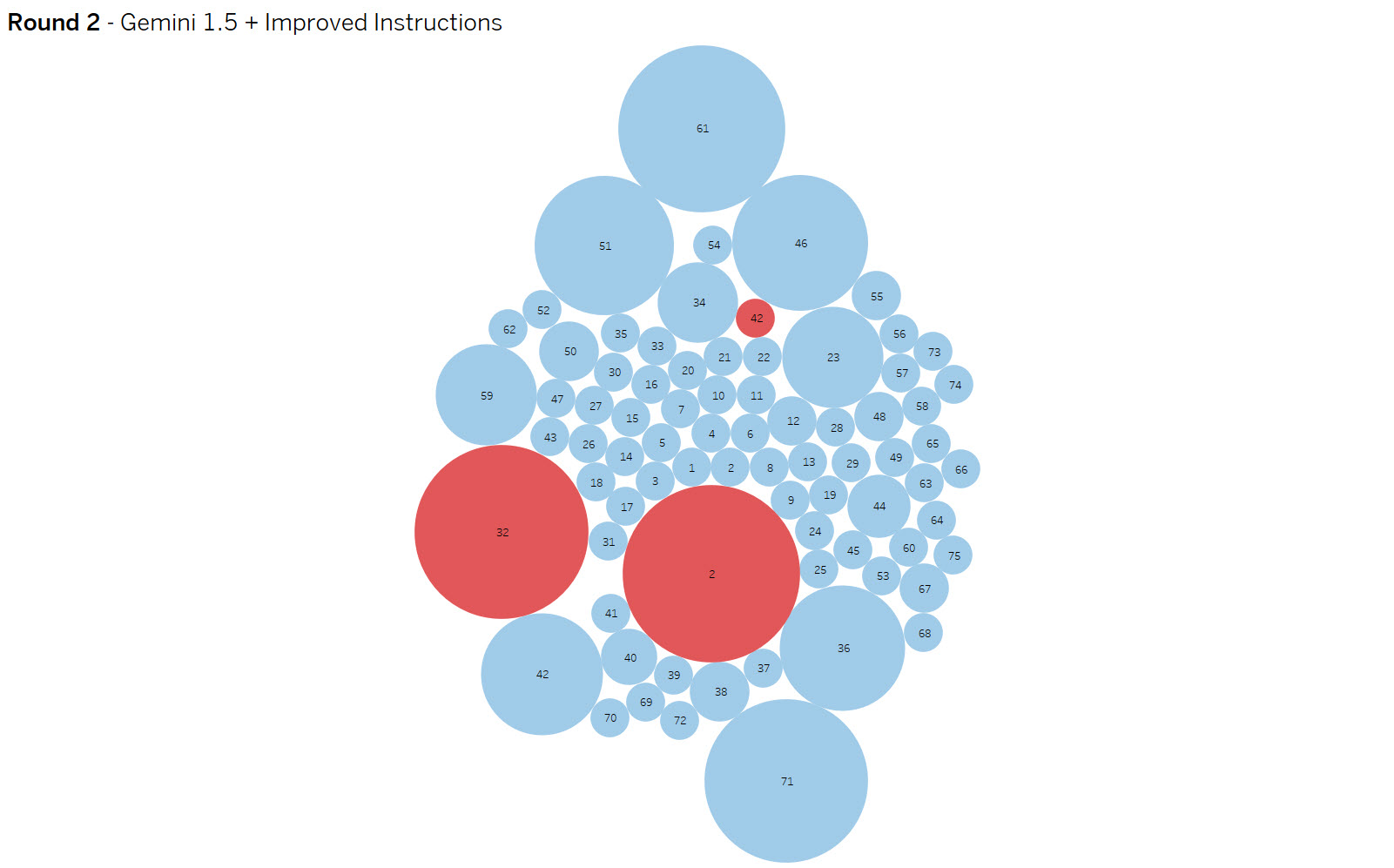
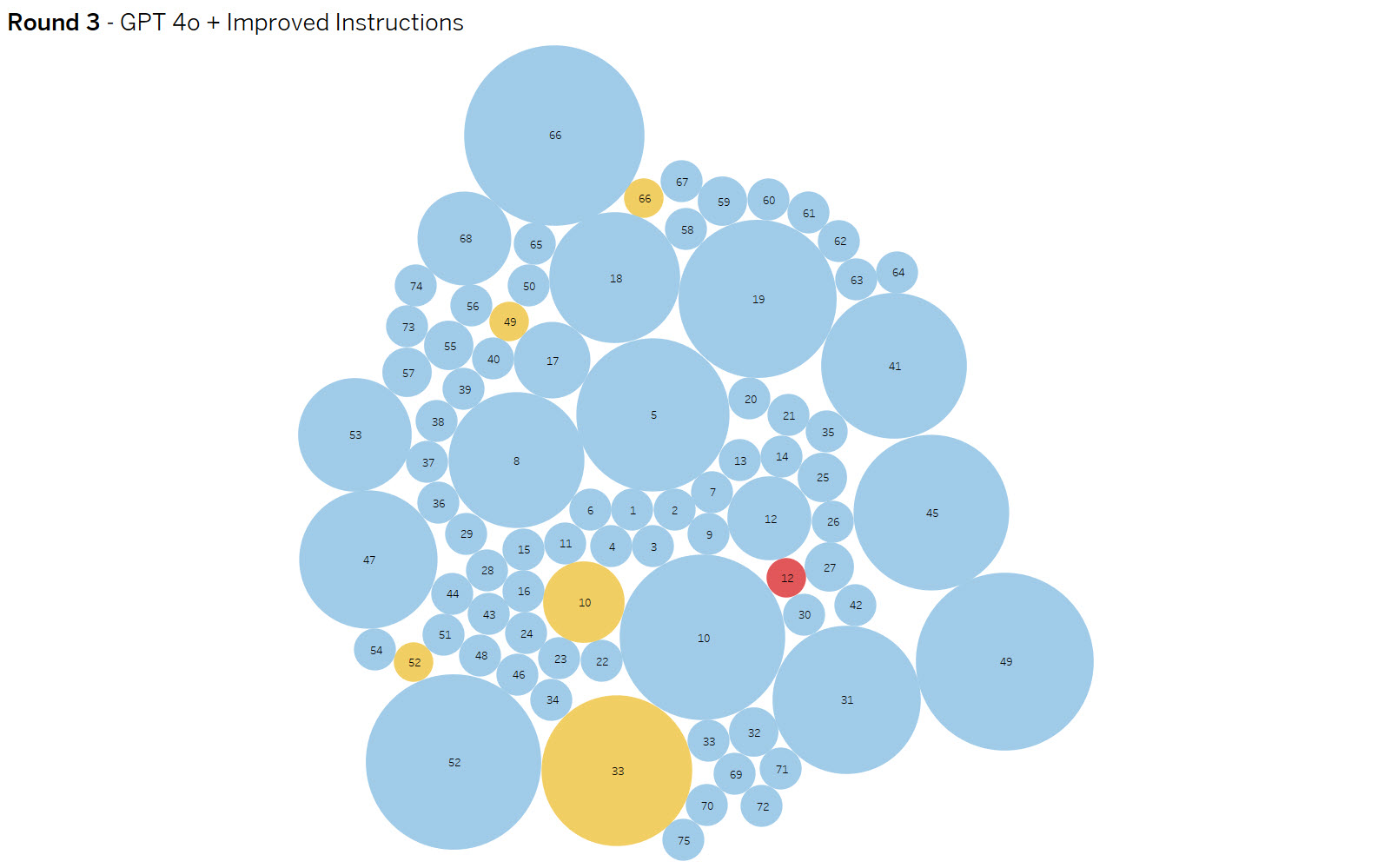
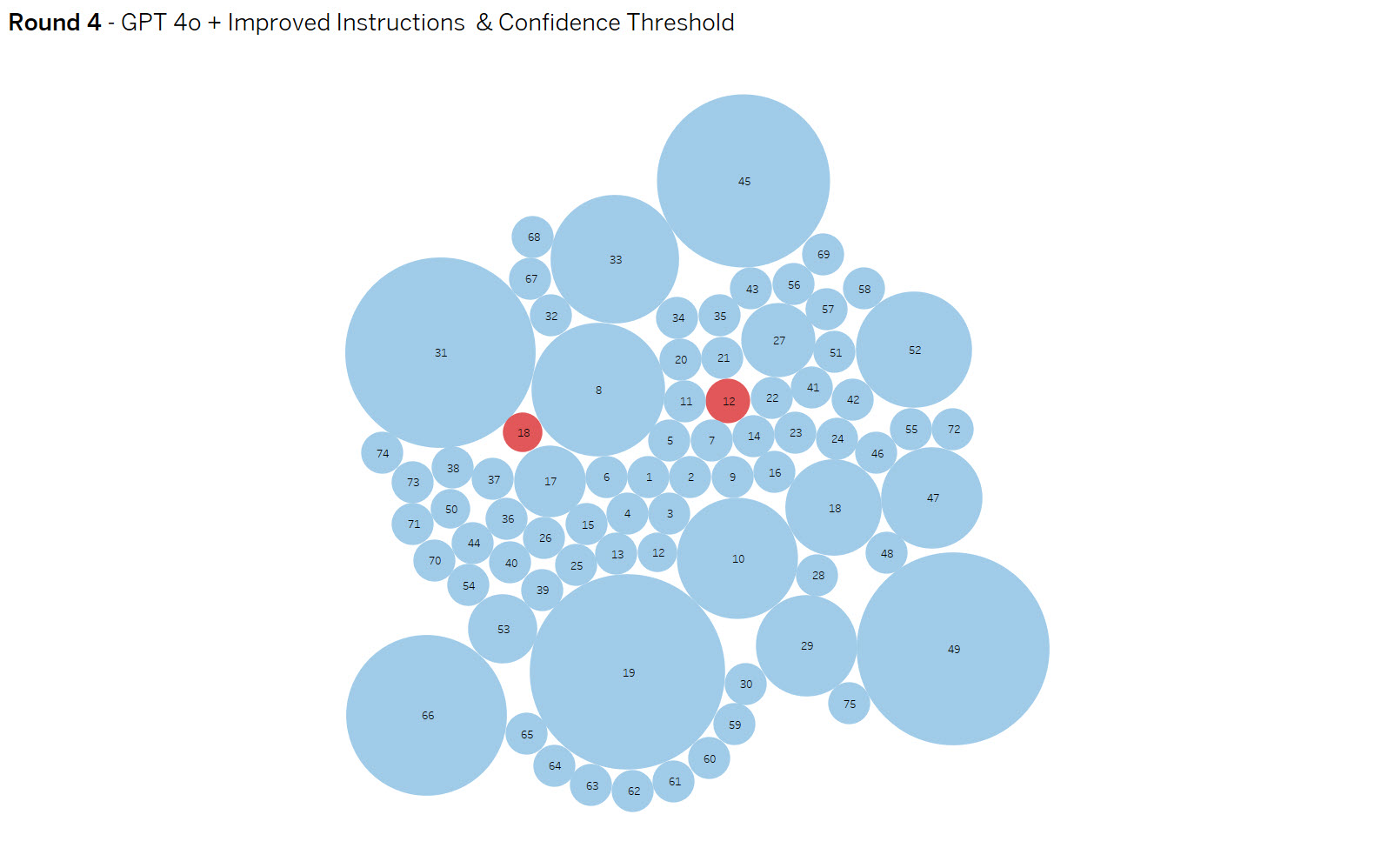
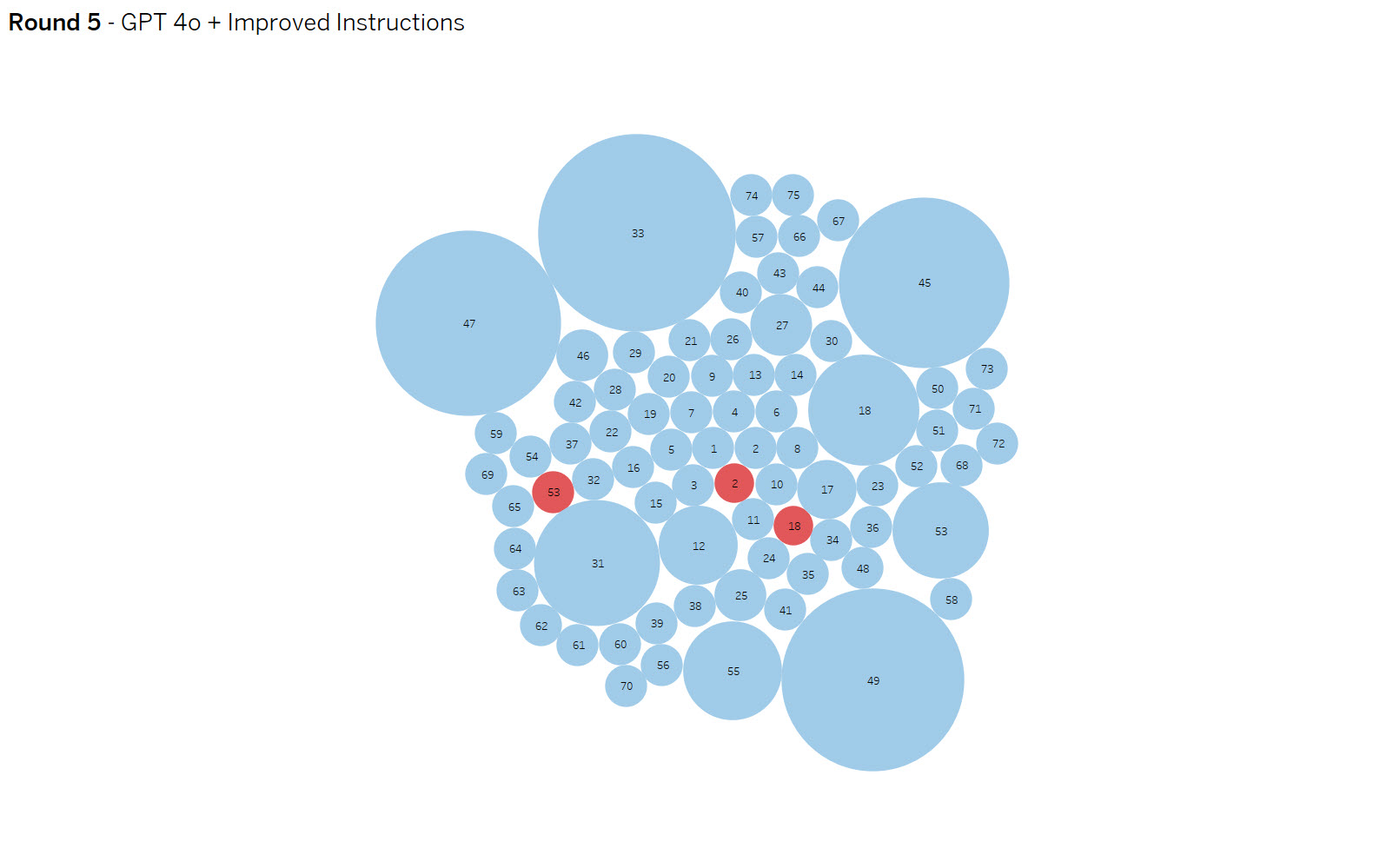
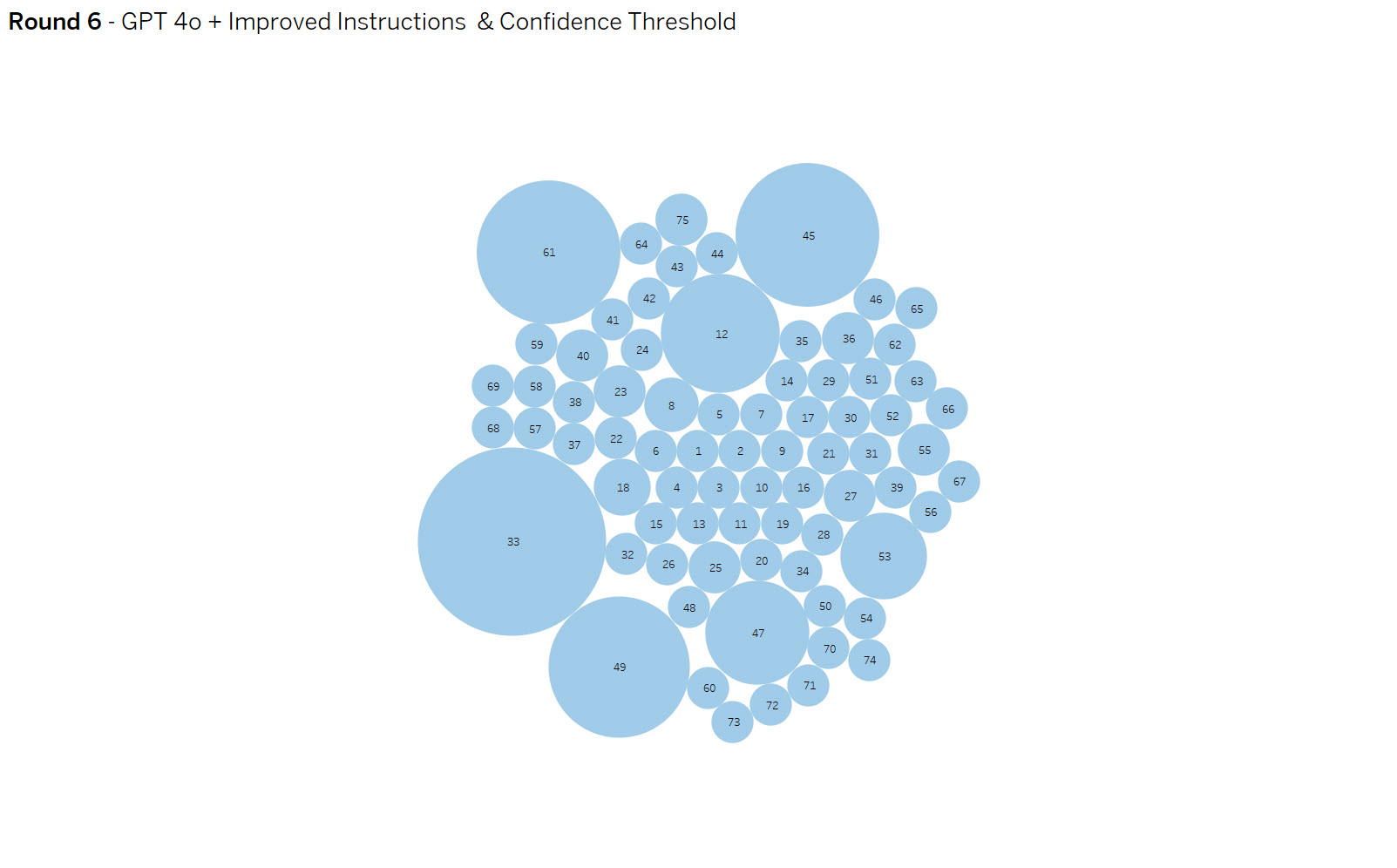
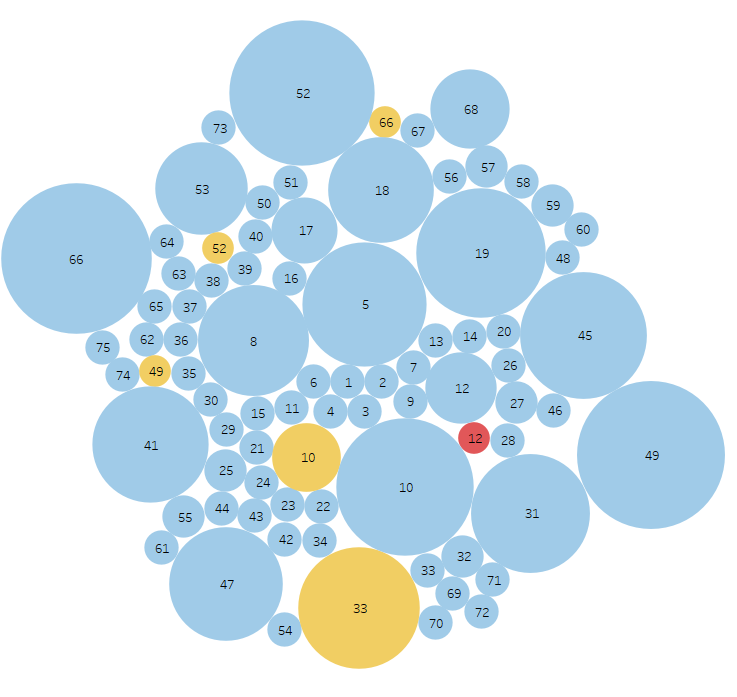
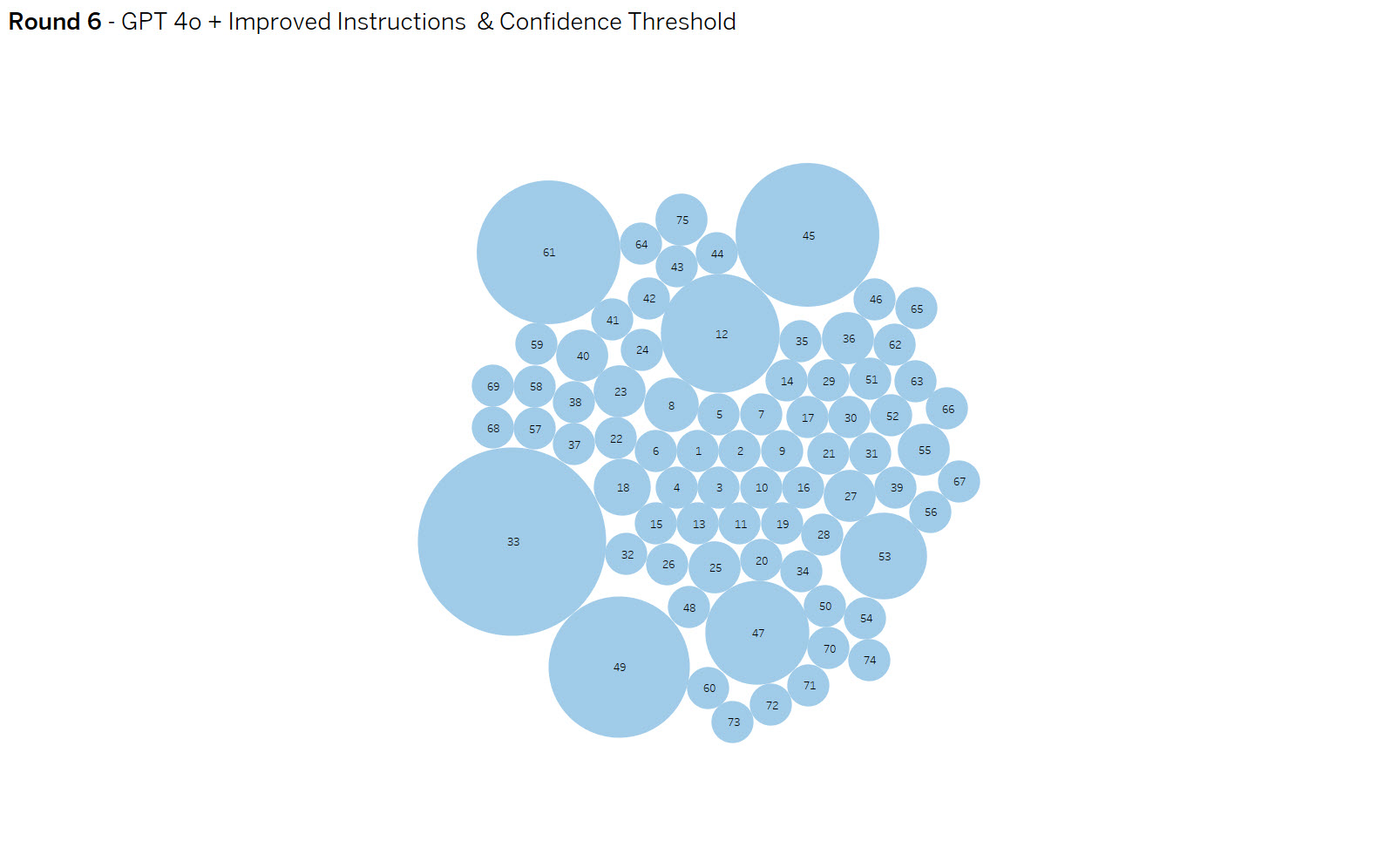
Yellow dots are false positives and reds are false negative results. The dot size indicates the amount of variance in results. The goal is to eliminate false positives and negatives while increasing consistency.
Background
After learning about my previous experience supporting data extraction products and work utilizing LLMs for document categorization and extraction, a contact asked me to develop a proof of concept to help determine the feasibility for utilizing LLMs for scanning various types of form inputs and saved data for a semantic categorization project. The challenge was that the input data could come in come in a variety of formats, without labels, embedded in HTML or JSON, and couldn’t necessarily be identified with specific keywords but required human like judgement. The hypothesis was that an LLM would succeed at this task, given it’s ability to ignore various formatting and understand language context.
The hypothesis was that an LLM would succeed at this task given it’s ability to ignore varied formatting while understanding language context.
The Plan
- Develop a project in Python to: intake test data, interact with the LLM and save results to a database
- Create complex and varied synthetic test data to represent a wide variety of potential inputs
- Write prompt context that would instruct the LLM on it’s task
- Test, iterate, and improve the system by adjusting the:
- prompt context
- AI model
- confidence threshold
- Analyze the data and develop visuals to help determine if the POC was a success and warranted further investment.
Execution
Coding the Project
For this project I utilized:
PyCharm for an IDE, Gemini Advanced and ChatGPT to write about 500 lines of code that:
- Read in test data, looped through, and sent it to a processing function
- Validated the data structure, combined it with the “Context” and sent it to a variety of models
- Received the data back from the LLM and validated it’s structure
- Combined the response with relevant metadata on the model and context
- Saved the run results to a database
Developing Test Evals
I chose to develop 75 synthetic test payloads with as much variety as I possible using Gemini Advanced, Chat GPT 4o, and Claude 3.7. For a production project, 500+ test cases may be more appropriate.
I asked the LLMs to develop test payloads in a JSON format, with a high level of creativity and variety, I gave samples of test data, but asked them to be creative and attempt to hide the data in the samples. I asked the LLM to score the payload on whether it should pass or fail the scanner. I reviewed the payloads and found that the LLMs did an excellent job of scoring the test payloads. Of 75, only 2 were incorrectly categorized when being created.
Testing and Analysis
Goal: increase accuracy (correct responces) and precision (lower variability), by manipulating the confidence threshold, the prompt context and using the best model for the job.
Approach: Run 5-10 repeat requests for each test payload for each model reviewing for both correctness and standard deviation in the LLMs confidence.
Round 1 – Gemini 1.5 vs Gemini 2.0
Summary: With my initial context, the two models tested achieved ~93% accuracy including 7 false positives and 2 false negatives.
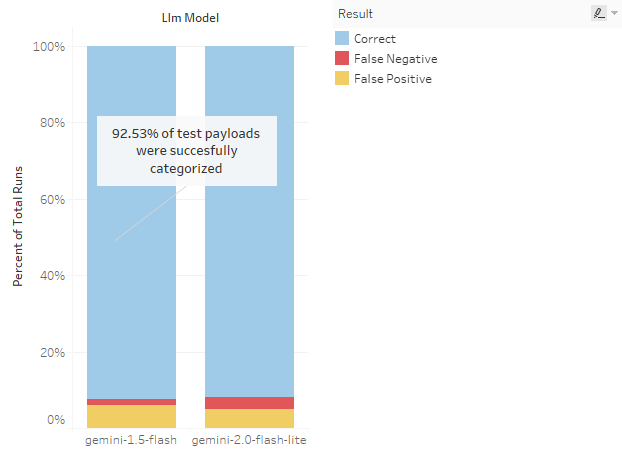
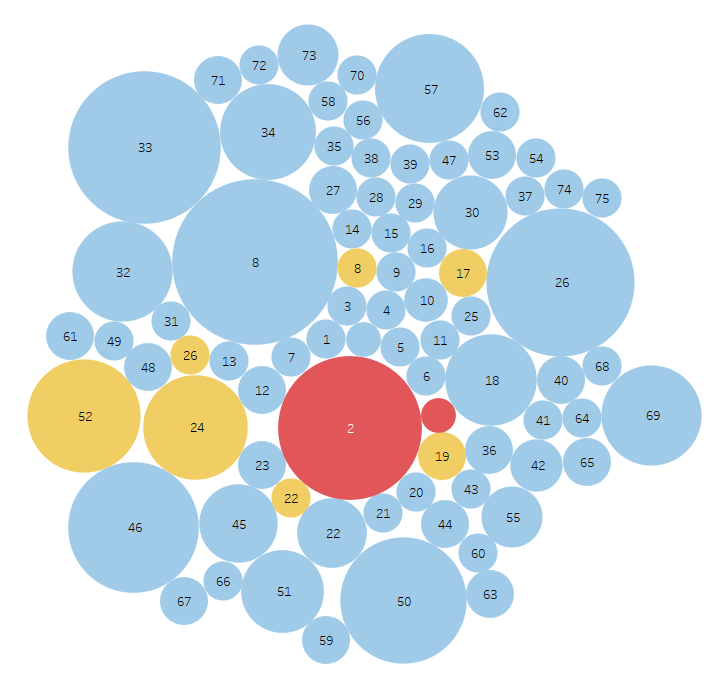
Round 2 – Gemini 1.5 vs Gemini 2.0 – Improved Instructions
Summary: Improved context (aka prompt engineering), resulted in eliminating the false positives resulting in 97% accuracy and 3 false negatives.

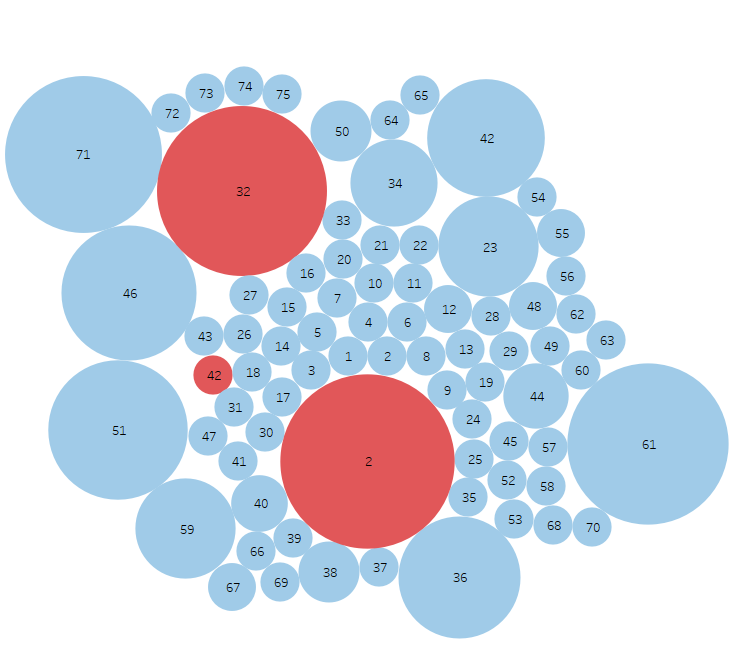
Round 3 – Gemini 2.0 vs OpenAI gpt-4o + improved instructions
Summary: I improved the context adding a far greater number of explicit examples, as well tested OpenAI gpt-4o. The Chat GPT model along with improved context eliminated all but one false negatives, but introduced a handful of false positives. Reviewing the data revealed raising the confidence threshold to .75 could eliminate the false positives.
Investigating further, I found that the majority of the false positives could be eliminated by increasing the confidence threshold from .5 to.75, while not increasing the risk of false negatives.
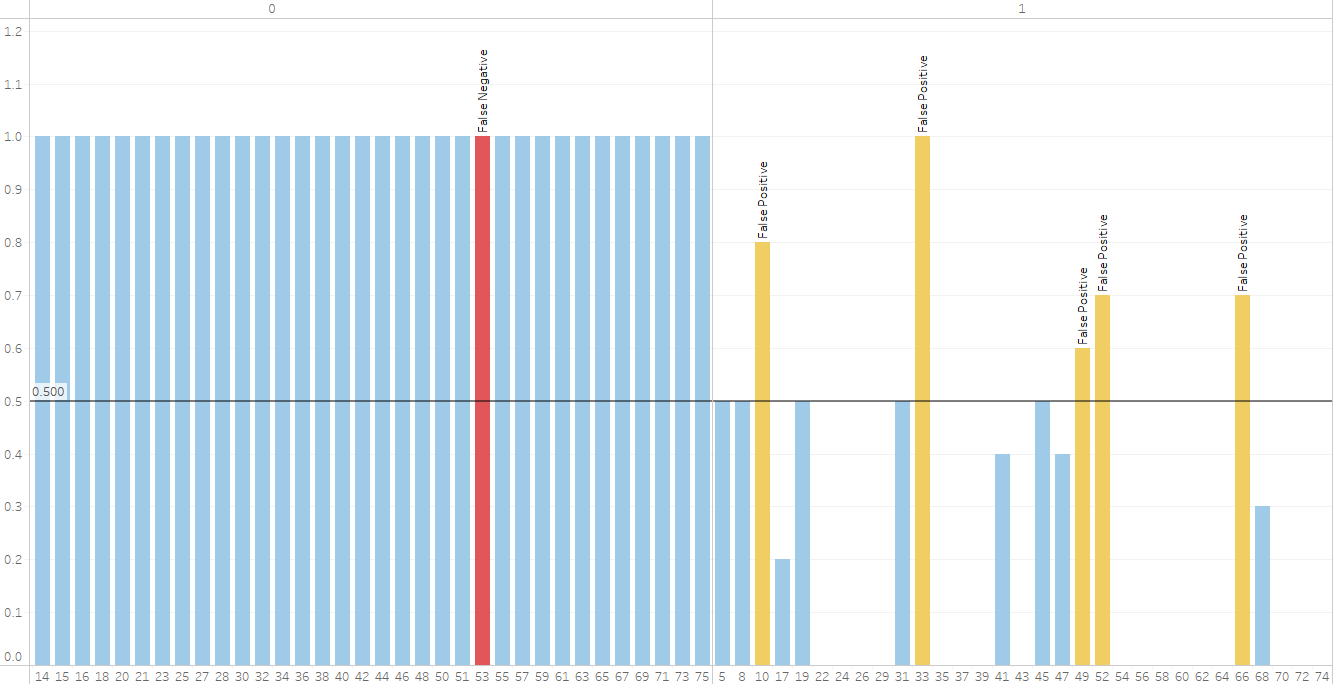
Round 4 – OpenAI gpt-4o improved instructions
Summary: Tweaked context and raising the confidence threshold to .75 resulted in 99% categorization accuracy across all runs, but with two false negatives.
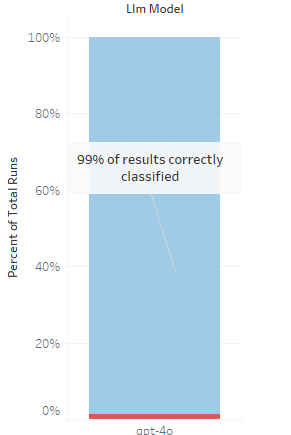
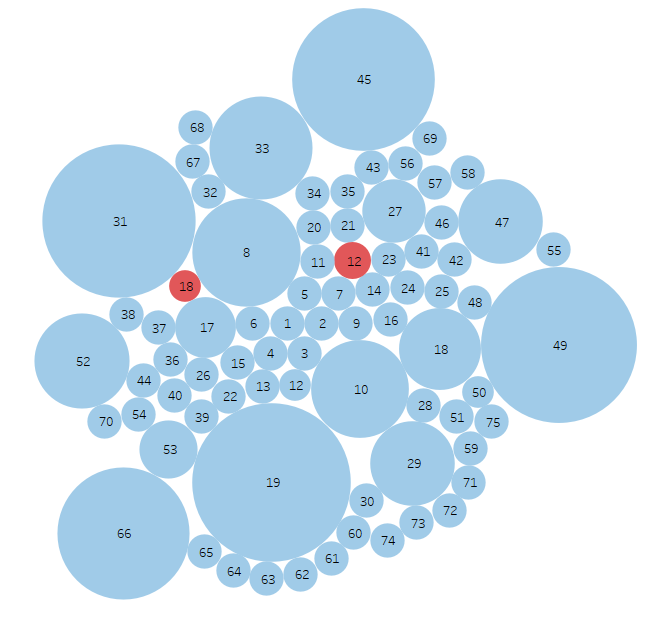
Round 5 – OpenAI gpt 4o improved instructions
Summary: I simplified the context to make it slightly more general, hoping to catch more edge cases, the result was less variability, but without eliminating the false negatives. Reviewing the confidence data revealed that with this updated context variability was decreased, but the confidence threshold of .75 was now too high.
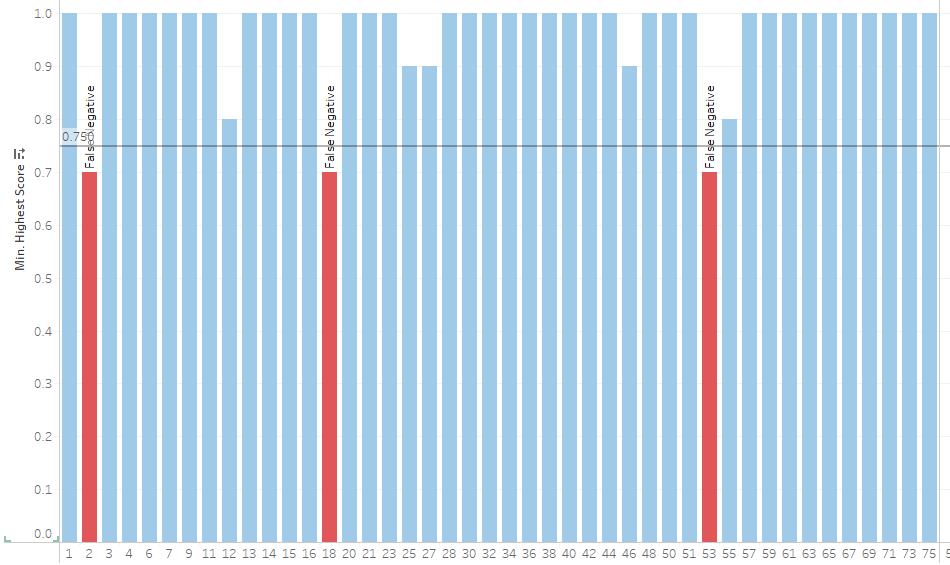
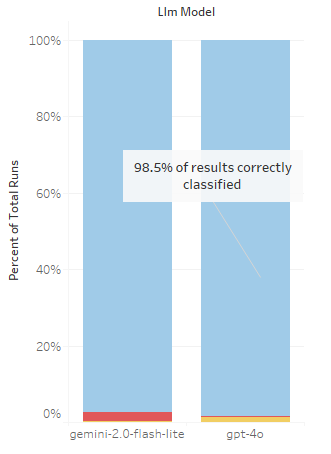
Round 6 (SUCCESS) – OpenAI gpt 4o improved instructions + Confidence Threshold
Summary: With one final update to the prompt context and adjusting the confidence threshold to .65, the model was able to achieve 100% accuracy in categorizing the 75 test payloads.
GPT 4o with the refined prompt exhibited great understanding of the task, as well as willingness to hunt through every field and complex value strings of HTML and Json in order to look for it’s target.
Next Steps
Given this was a proof of concept project, my contact and I agreed the data was sufficient at this stage to answer whether or not this approach could work. If this project was being implemented into production these are the next steps I would consider:
- Developing hundreds more test cases, ideally using a mix of real world data as well as synthetic test data
- Comparing additional models from Google and OpenAI and other providers – I tested three models, but there are additional models available with frequent new releases that are meant to reduce costs or reduce latency